

基于 MATLAB 的车牌识别系统(VLPR-Based-On-MATLAB)——数字图像处理期末大作业
基于 MATLAB 的车牌识别系统(VLPR-Based-On-MATLAB)——数字图像处理期末大作业
任务描述
项目名称
基于MATLAB的车牌识别系统
项目 Repo
https://github.com/LeonYew-SWPU/VLPR-Based-On-MATLAB
项目资源
- MATLAB R2024a Update 1 (24.1.0.2571086) App Designer
- git version 2.39.1.windows.1
简介(TODO:添加图片示例)
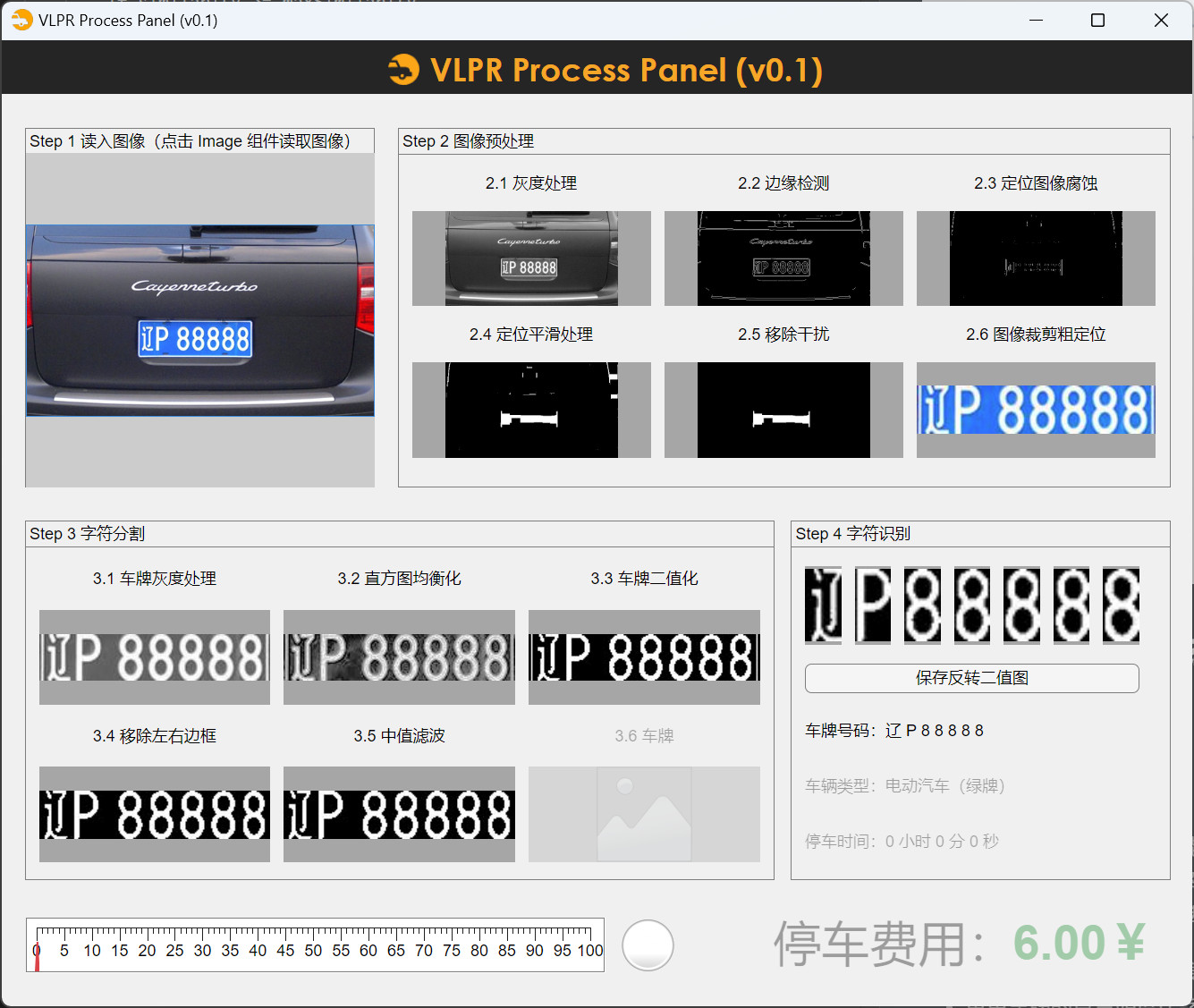
通过图像处理算法来处理摄像头拍摄到的车辆照片,定位,矫正,裁切,识别车牌读出文字。
使用说明(TODO)
额外功能特点
- 识别车牌文字
- 语音读出车牌(利用 Microsoft 文字转语音包)
- 改进:卷积神经网络算法识别车牌
- 做出管理服务端
- 查看当前车库实时情况
- 查看停车时间
- 查看车辆类别(临时车、业主车、服务车)
- 做出入库出库两个客户端
设计思路
问题定义
目标:基础目标是,基于MATLAB App Designer设计一个能够自动识别车辆车牌号码的系统。
输入:包含车辆的图像或视频。
输出:识别出的车牌号码。
需求分析
功能需求:实现车牌定位、图像矫正、字符分割、字符识别等功能。
性能需求:高准确率、低误识率、快速识别。
用户需求:易于使用、稳定可靠。
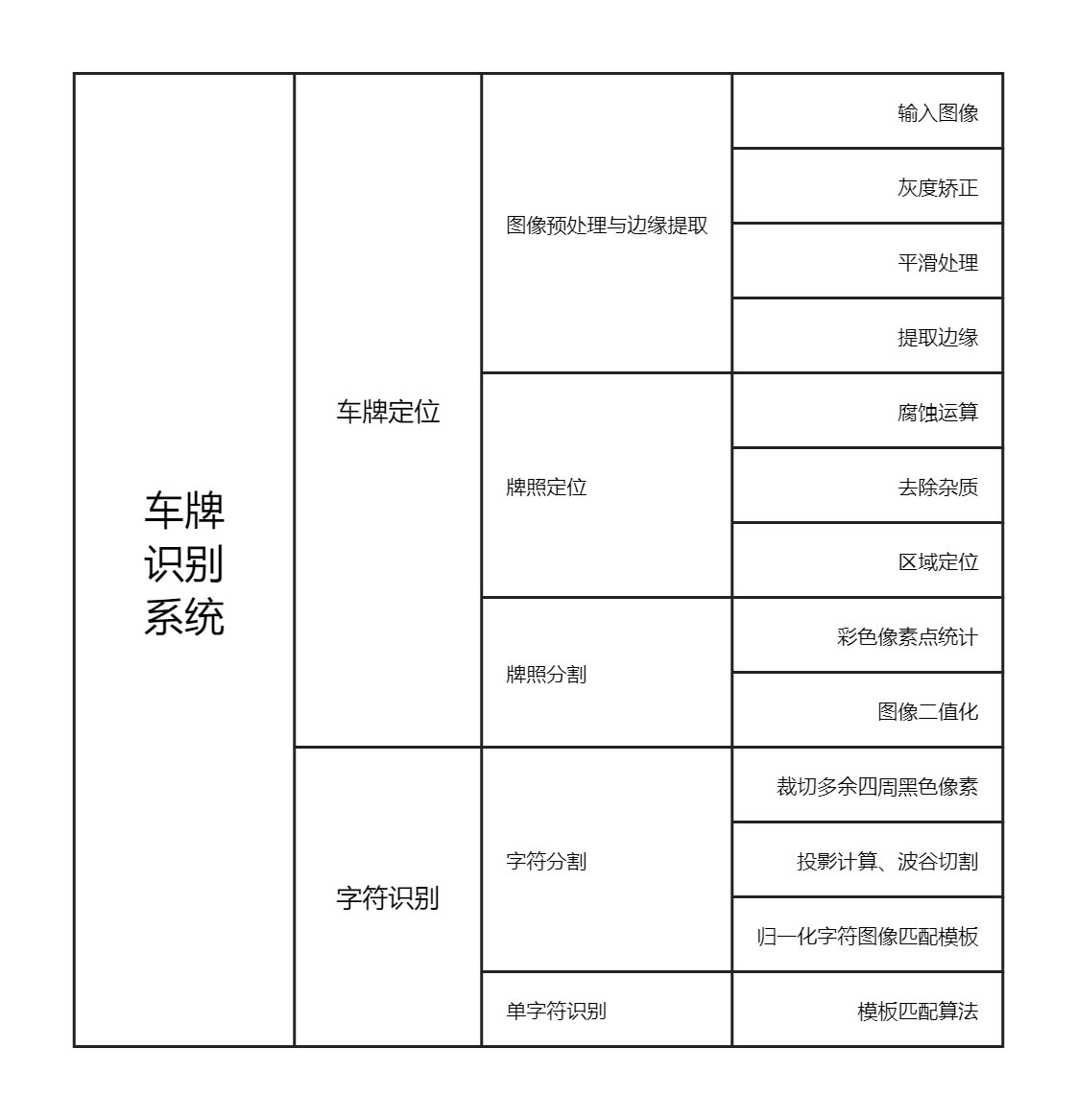
系统功能与算法设计
车辆牌照识别整个系统主要是由车牌定位和字符识别两部分组成。
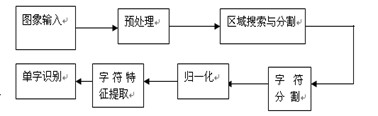
工作流程
- 当行驶的车辆经过时,触发埋设在固定位置的传感器,系统被唤醒处于工作状态;一旦连接摄像头光快门的光电传感器被触发,设置在车辆前方、后方和侧面的相机同时拍摄下车辆图像;
- 由摄像机或CCD 摄像头拍摄的含有车辆牌照的图像通视频卡输入计算机进行预处理,图像预处理包括图像转换、图像增强、滤波和水平较正等;
- 由检索模块进行牌照搜索与检测,定位并分割出包含牌照字符号码的矩形区域;
- 对牌照字符进行二值化并分割出单个字符,经归一化后输入字符识别系统进行识别。
功能实现
项目搭建
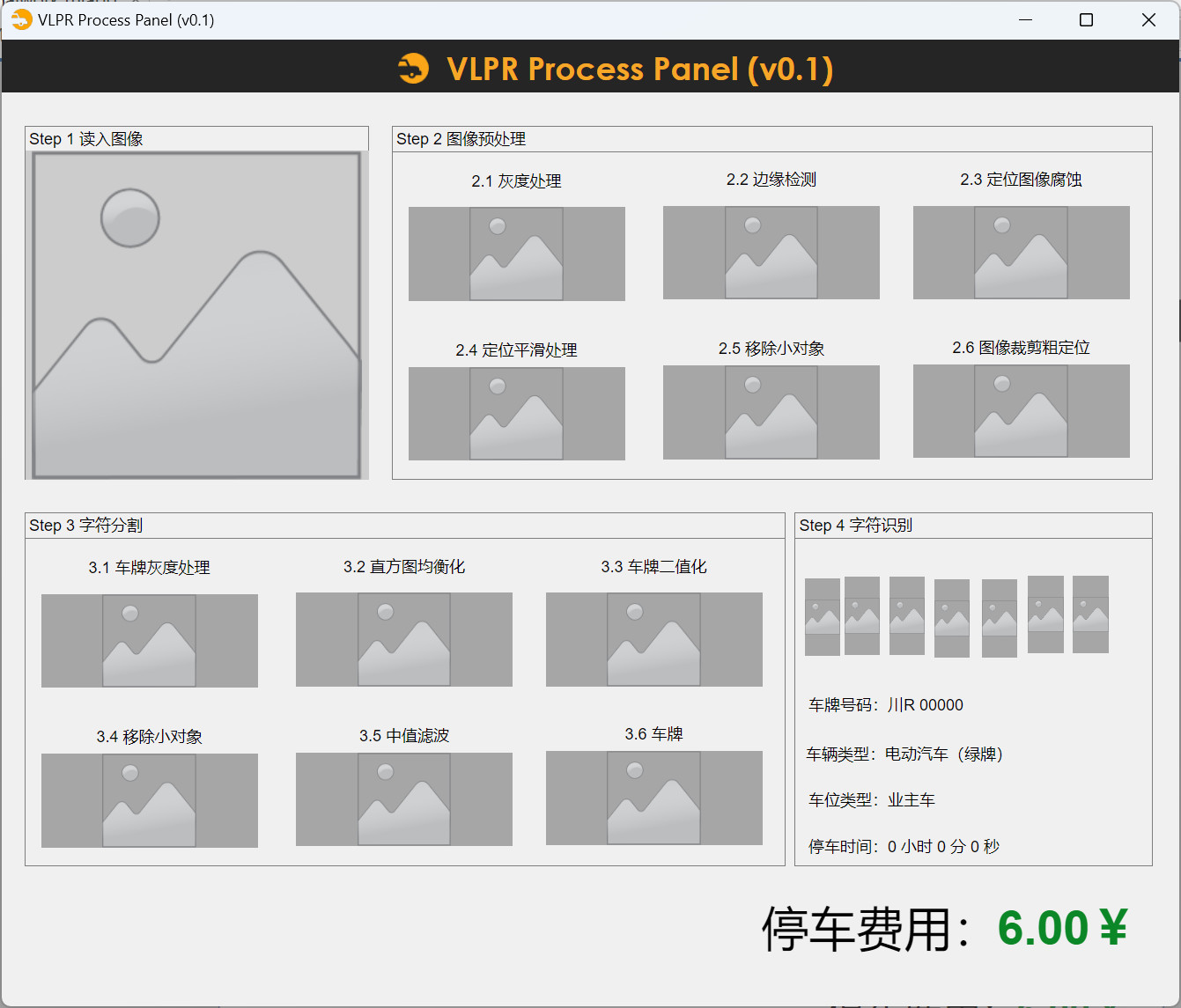
根据功能需求,设计大致界面,为了方便调试和观察图像处理过程,先设计服务端界面,用于展示图像处理的数据。
创建 Matlab App
导航窗格 > APP > 设计 App
App Designer > 新建 > 空白 App
使用组件创建 GUI 界面
保存文件,创建 Git 仓库
在 Github 上创建项目,Code > HTTPS > 复制命令
在要保存项目的地方 Shift + 右键,打开命令行输入:
git clone https://github.com/LeonYew-SWPU/VLPR-Based-On-MATLAB.git
进入文件夹,将 .mlapp 和其他相关文件拖入项目文件夹。
Shift + 右键,打开命令行依次输入:
git add .
git commit -m "Init Repo Files"
git push origin main
完成向 Github 仓库的 Push,此时,再登录 Github 能看到更改的文件,后续每完成一个功能就 Commit,方便项目版本回溯。
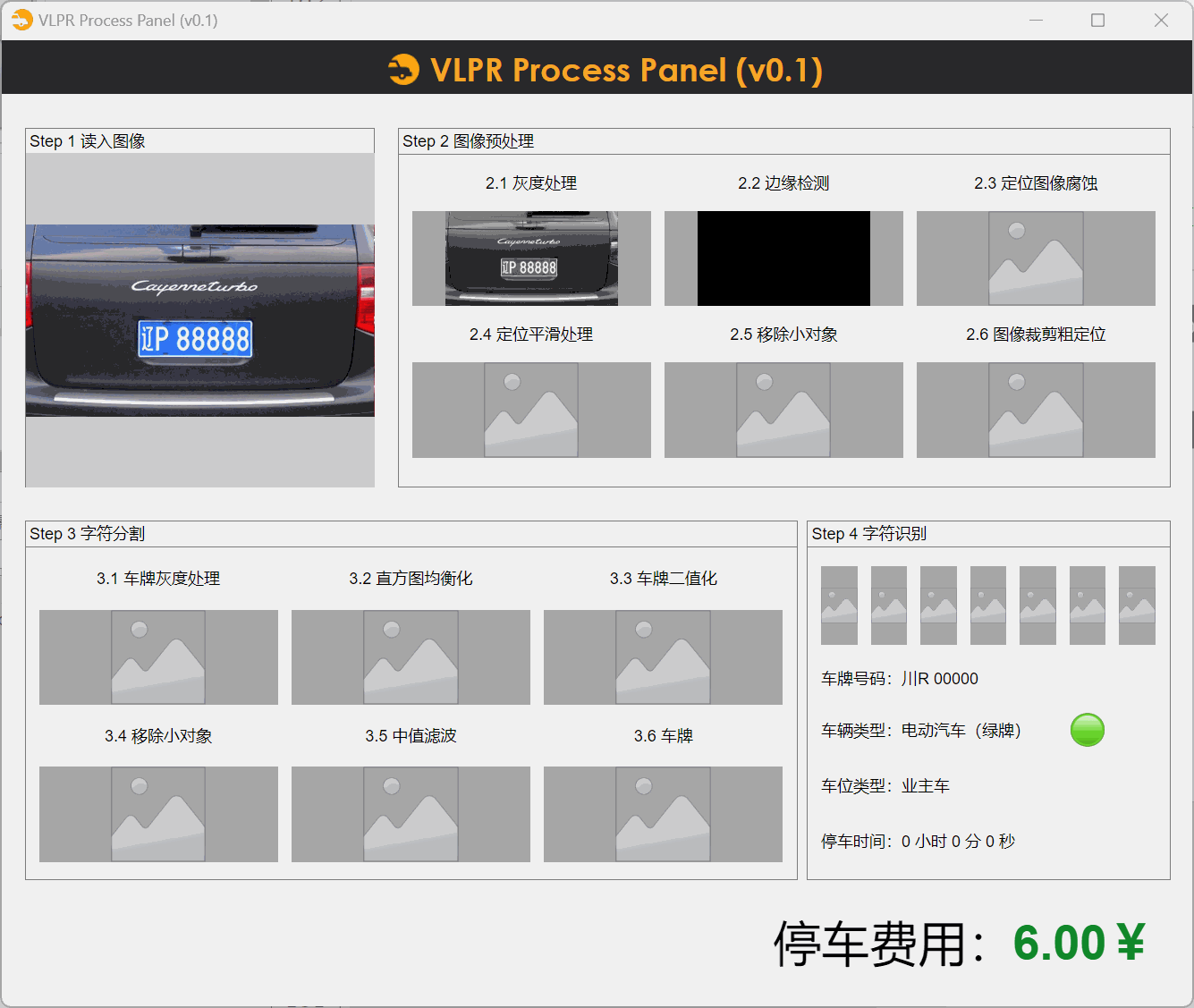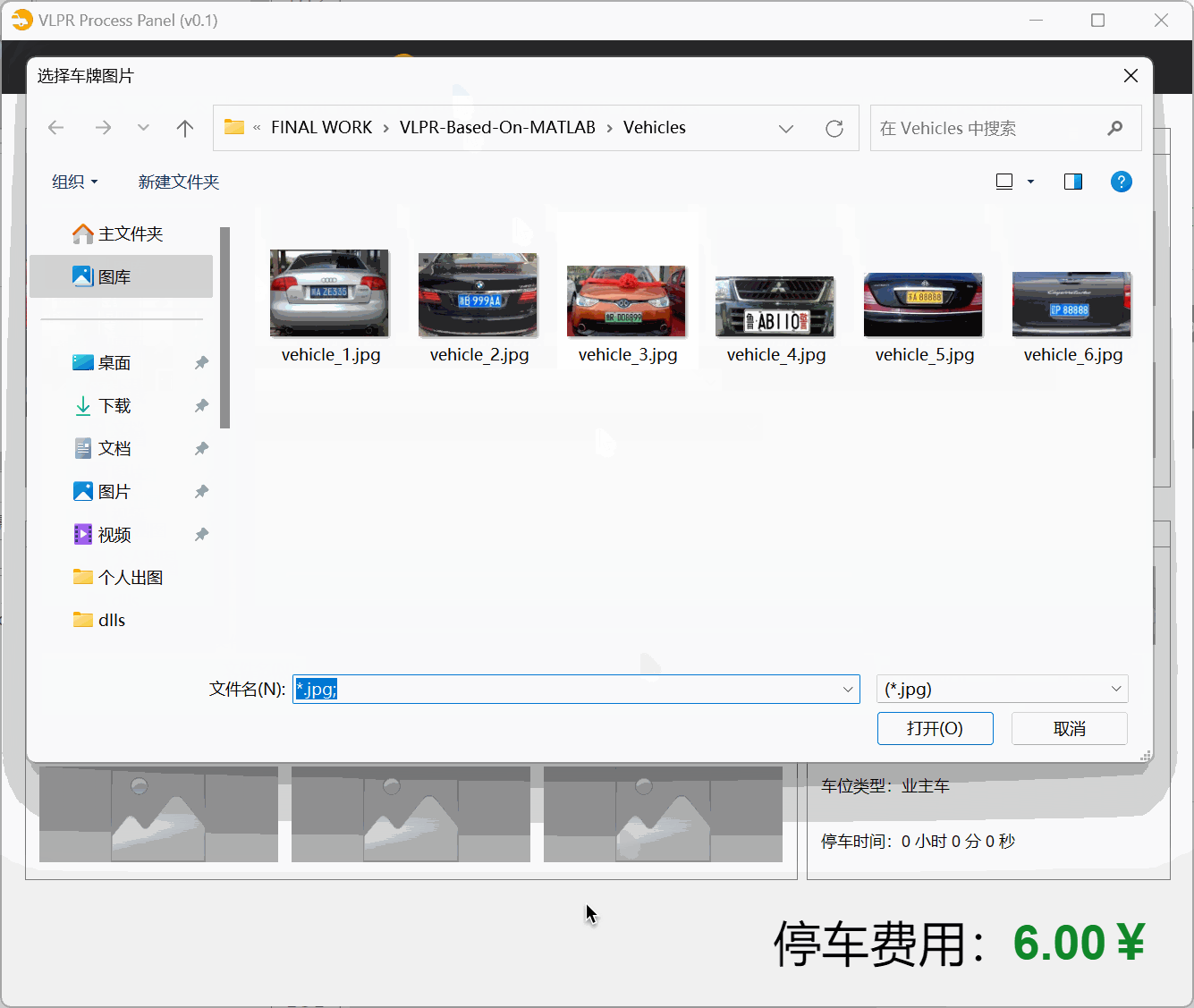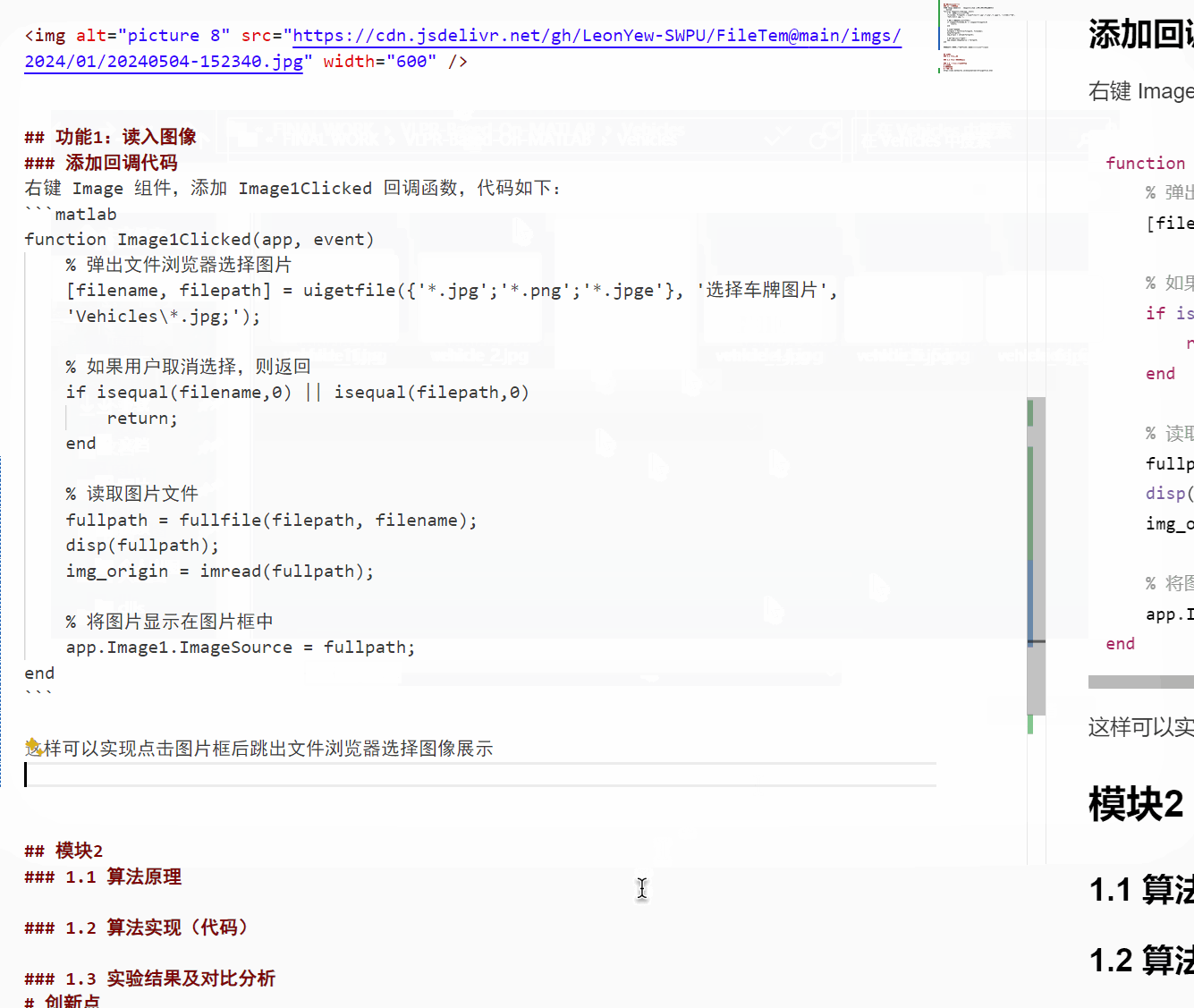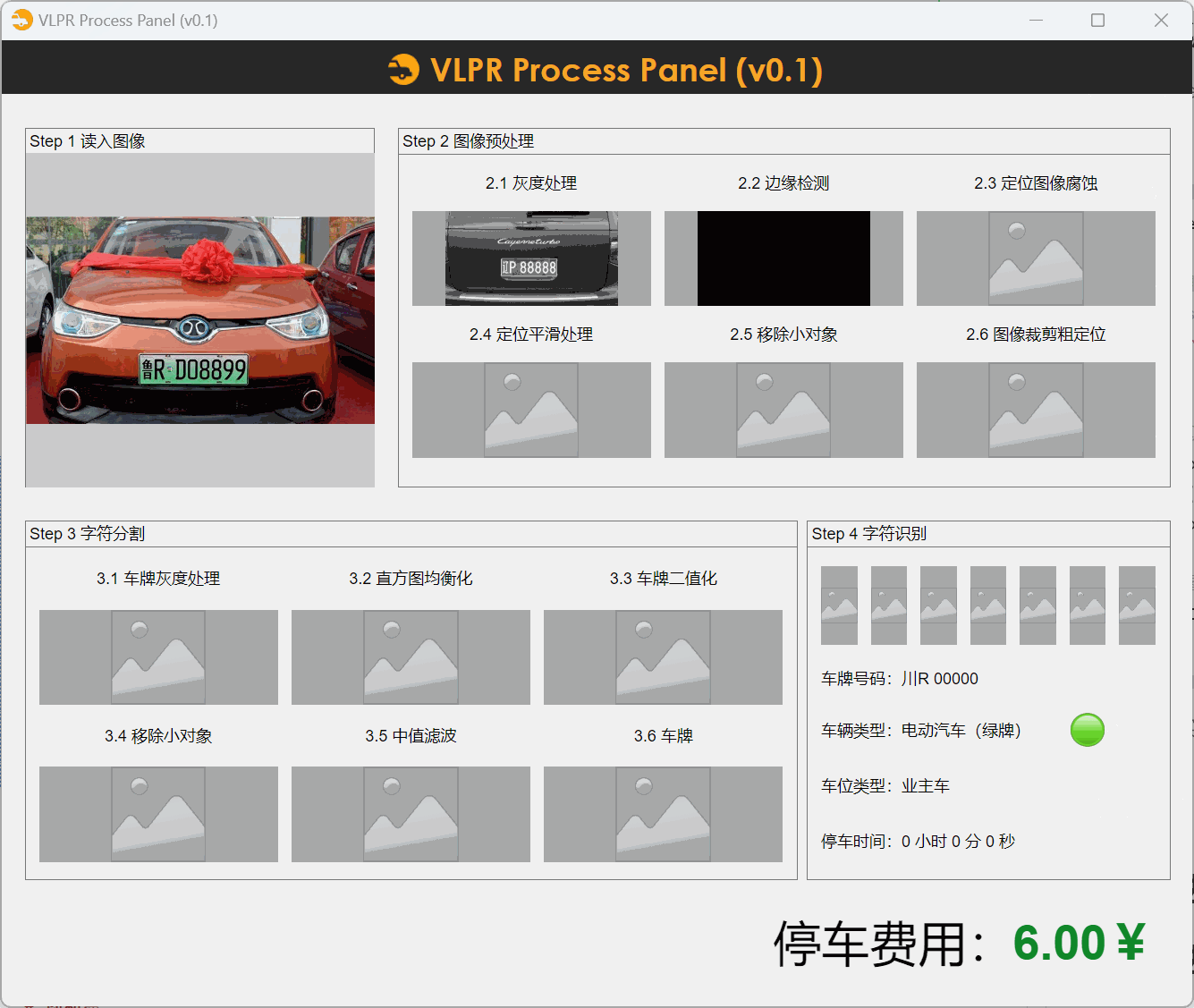
步骤1:读入图像
添加回调代码
右键 Image 组件,添加 Image1Clicked 回调函数,代码如下:
function Image1Clicked(app, event)
% 弹出文件浏览器选择图片
[filename, filepath] = uigetfile({'*.jpg';'*.png';'*.jpge'}, '选择车牌图片','Vehicles\*.jpg;');
% 如果用户取消选择,则返回
if isequal(filename,0) || isequal(filepath,0)
return;
end
% 读取图片文件
fullpath = fullfile(filepath, filename);
disp(fullpath);
img_origin = imread(fullpath);
% 将图片显示在图片框中
app.Image1.ImageSource = fullpath;
end
这样可以实现点击图片框后跳出文件浏览器选择图像展示(目前有点bug,选择完图片后会自动最小化..)
步骤2:灰度转换
算法原理
利用 Matlab 的函数库,将 RGB 转化为单通道灰度图像,以便继续进行边缘计算以及开闭运算等,进一步计算出车牌的蒙版。
算法实现
% func21:灰度处理
function img_out = func21(app,img)
app.img_21 = im2gray(img);
img_out = cat(3, app.img_21, app.img_21, app.img_21);
img_out = uint8(img_out);
end
实验结果

步骤3:边缘检测
算法原理
边缘检测的核心就是计算图像的灰度梯度,梯度比较大的地方自然就是图像中物体的边缘,以 Sobel 算子的算法为例:
它通过计算图像中每个像素点的梯度值来实现边缘检测。Sobel算子主要包括以下步骤:
灰度化: 首先,将彩色图像转换为灰度图像,因为边缘检测通常在灰度图像上进行。
计算梯度: 对灰度图像应用Sobel算子,分别计算每个像素点的水平方向梯度和竖直方向梯度。Sobel算子的模板如下所示:
Gx = [-1 0 1; -2 0 2; -1 0 1]; % 水平方向梯度
Gy = [-1 -2 -1; 0 0 0; 1 2 1]; % 竖直方向梯度
其中,Gx和Gy分别表示水平和竖直方向的Sobel算子模板。对于每个像素点,分别与这两个模板进行卷积运算,得到该点的水平方向和竖直方向梯度。
**梯度合并:**将每个像素点的水平和竖直方向梯度合并成一个梯度幅值,通常使用以下公式计算:
GradientMagnitude = sqrt(Gx^2 + Gy^2); % 梯度幅值
梯度方向: 计算每个像素点的梯度方向,通常使用以下公式:
GradientDirection = atan2(Gy, Gx);
其中,GradientDirection表示梯度方向,使用atan2函数可以得到角度值。
非极大值抑制: 对梯度幅值图像进行非极大值抑制,目的是保留图像中的细线条边缘,去除其他杂散的边缘响应。
边缘二值化: 根据设定的阈值将梯度幅值图像进行二值化处理,得到最终的边缘图像。
算法实现
在 MATLAB 中,可以非常方便的使用 edge 来计算图像的边缘,也可以通过 imgradient 函数计算图像的梯度,再根据需要设置梯度处理的系数,更加细致的获取图像边缘。
% func22:边缘检测
function img_out = func22(app)
% 使用 Canny 边缘检测算法检测边缘
app.img_22 = edge(app.img_21, 'Sobel');
img_out = app.img_22 * 255; % 2 值图转化为 RGB 图需要把 1 转化为 255
img_out = cat(3, img_out, img_out, img_out);
img_out = uint8(img_out);
end
实验结果

步骤4:腐蚀运算
算法原理
在得到边缘之后,我们还不能确定车牌的边缘在哪里,但是我们知道车牌的形状是正方形的,所以可以通过定义线性结构元素并通过腐蚀运算,来消除掉斜线和长横线的边缘,留下车牌的边缘。
算法实现
% func23:图像腐蚀运算
function img_out = func23(app)
% 定义腐蚀结构元素
se = [1;1;1];
% 对边缘二值图像进行腐蚀运算
app.img_23 = imerode(app.img_22, se);
% 显示结果
img_out = app.img_23 * 255;
img_out = cat(3, img_out, img_out, img_out);
img_out = uint8(img_out);
end
实验结果

步骤5:图像填充
算法原理
通过边缘检测得到了物体边缘之后,我们需要通过对图像进行闭运算来得到车牌的区域,进而得到蒙版以及位置。
算法实现
% func24:填充图像
function img_out = func24(app)
se = strel('rectangle',[25,25]); %矩形结构元素
app.img_24 = imclose(app.img_23,se);%图像聚类、填充图像
% 得到结果
img_out = app.bw2rgb(app.img_24);
end
实验结果
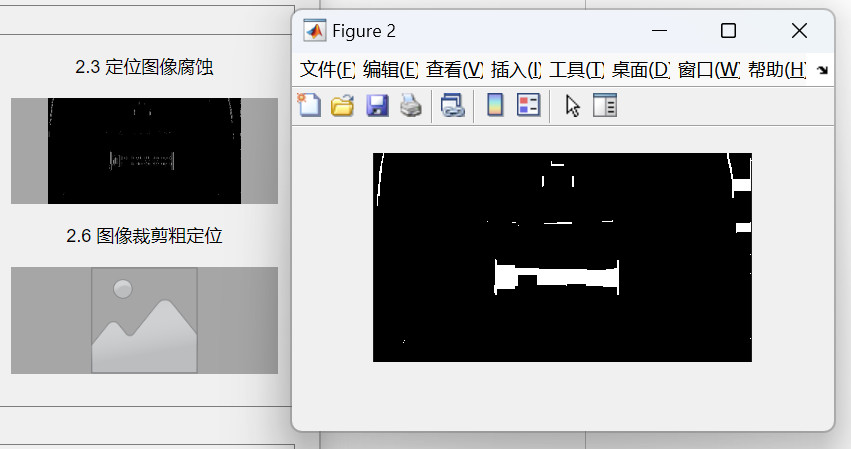
步骤6:移除干扰
算法原理
通过开运算沿着边缘填充后,我们能得到车牌的区域,但是车辆的其他线条也被填充起来了,我们需要把这些区域通过开运算 bwareaopen 函数,去除二值图像中面积小于指定阈值的连通区域。bwareaopen 函数原理如下:
- 输入参数:bwareaopen 函数接受两个输入参数,第一个参数是二值图像,第二个参数是一个面积阈值,表示要保留的连通区域的最小面积。
- 连通区域标记:首先,bwareaopen 函数使用 MATLAB 中的 bwlabel 函数对输入的二值图像进行连通区域标记,得到每个连通区域的标记值。
- 计算连通区域面积:然后,对于每个连通区域,bwareaopen 函数计算该区域的像素个数,即该区域的面积。
- 面积过滤:接着,bwareaopen 函数将计算得到的连通区域面积与指定的阈值进行比较,保留面积大于等于阈值的连通区域,将面积小于阈值的连通区域视为噪声,将其像素置为 0(即去除)。
- 输出结果:最后,bwareaopen 函数返回去除小面积连通区域后的二值图像。
算法实现
% func25: 移除干扰元素
function img_out = func25(app)
app.img_25=bwareaopen(app.img_24,2000);%从对象中移除面积小于2000的小对象
% 得到结果
img_out = app.bw2rgb(app.img_25);
end
实验结果
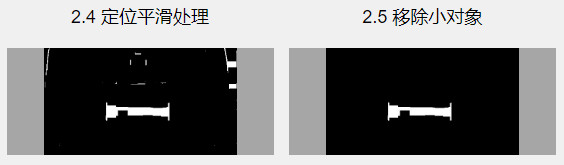
步骤7:根据车牌区域裁切原图
算法原理
通过对车牌边缘填充和去除干扰,我们已经能得到车牌的大致区域,我们再通过对图像区域进行白色像素,统计每行每列的白色像素点个数,从而可以获取到哪一行到哪一行的白色像素是多的,哪一列到哪一列的白色像素是的。
再利用得到的行列数字,对原图进行裁切,就能得到车牌图像的大致区域。
算法实现
% func26:车牌粗定位
function img_out = func26(app)
[y,x]=size(app.img_25);%size函数将数组的行数返回到第一个输出变量,将数组的列数返回到第二个输出变量
app.img_26=double(app.img_25);
%%%%%%%%%% A. 确定行的起始位置和终止位置 %%%%%%%%%%%
Y1=zeros(y,1);%产生y行1列全零数组
for i=1:y
for j=1:x
if(app.img_26(i,j)==1)
Y1(i,1)= Y1(i,1)+1;%白色像素点统计
end
end
end
[temp,MaxY]=max(Y1);%Y方向车牌区域确定。返回行向量temp和MaxY,temp向量记录Y1的每列的最大值,MaxY向量记录Y1每列最大值的行号
% figure,subplot(2,2,2),plot(0:y-1,Y1),title('原图行方向像素点值累计和'),xlabel('行值'),ylabel('像素');
PY1=MaxY;
while ((Y1(PY1,1)>=8)&&(PY1>1))
PY1=PY1-1;
end
PY2=MaxY;
while ((Y1(PY2,1)>=9)&&(PY2<y))
PY2=PY2+1;
end
IY=app.img_origin(PY1:PY2,:,:);
%%%%%%%%%% B、确定列的起始位置和终止位置 %%%%%%%%%%%
X1=zeros(1,x);%产生1行x列全零数组
for j=1:x
for i=PY1:PY2
if(app.img_26(i,j,1)==1)
X1(1,j)= X1(1,j)+1;
end
end
end
% subplot(2,2,4),plot(0:x-1,X1),title('原图列方向像素点值累计和'),xlabel('列值'),ylabel('像数');
PX1=1;
while ((X1(1,PX1)<3)&&(PX1<x))
PX1=PX1+1;
end
PX3=x;
while ((X1(1,PX3)<3)&&(PX3>PX1))
PX3=PX3-1;
end
% 裁切原图,得到结果
img_out=app.img_origin(PY1:PY2,PX1:PX3,:);
end
实验结果

步骤8:车牌灰度化
算法原理
通过图像预处理得到了车牌图像之后,开始对车牌进行精细处理,再次之前,需要再度转化成灰度图便于进一步进行操作。
算法实现
% func31:灰度处理
function img_out = func31(app)
app.img_31 = rgb2gray(app.img_26);
img_out = cat(3, app.img_31, app.img_31, app.img_31);
img_out = uint8(img_out);
end
实验结果

步骤9:车牌直方图均衡化
算法原理
为了降低环境光照以及其他因素对车牌照片的影响,还需要对车牌照片进行直方图均衡化处理,增强图像的对比度和亮度,从而更好地提取车牌上的字符信息,提高识别准确率。
直方图均衡化原理如下:
-
计算灰度直方图:首先,对输入的灰度图像进行统计,得到其灰度直方图。灰度直方图表示不同灰度级别的像素在图像中的分布情况。
-
计算累积分布函数(CDF):根据灰度直方图,计算每个灰度级别的累积分布函数(CDF)。CDF表示小于或等于某一灰度级别的像素在图像中的累积比例。
-
映射像素值:根据CDF,将原始图像中每个像素的灰度级别映射到一个新的灰度级别,从而实现对图像的均衡化。映射公式为:
[
\text{new_pixel_value} = \text{CDF}(\text{original_pixel_value}) \times (\text{max_intensity} - 1)
]其中,(\text{original_pixel_value}) 表示原始图像中的像素值,(\text{CDF}) 表示累积分布函数,(\text{max_intensity}) 表示灰度级别的最大值(通常为 256)。
算法实现
% func32:直方图均衡化
function img_out = func32(app)
% 计算灰度直方图
histogram = imhist(app.img_31);
% 计算累积分布函数(CDF)
cdf = cumsum(histogram) / numel(app.img_31);
% 对图像进行直方图均衡化
app.img_32 = uint8(255 * cdf(app.img_31 + 1));
img_out = cat(3, app.img_32, app.img_32, app.img_32);
img_out = uint8(img_out);
end
实验结果

步骤10:车牌二值化
算法原理
为了更好的处理掉左右的边缘线条以及车牌上的小面积污点,需要再次对车牌进行二值化处理。代码涉及到的原理如下:
-
获取图像灰度范围:首先,获取车牌图像的最大灰度值 (c_{\text{max}}) 和最小灰度值 (c_{\text{min}})。
-
计算阈值:根据最大最小灰度值,计算二值化的阈值 (T)。这里使用的阈值计算公式为:
[ T = \text{round}(c_{\text{max}} - \frac{c_{\text{max}} - c_{\text{min}}}{3}) ]
其中,(\text{round}) 是取最接近的整数的函数。这个阈值计算方式是根据图像的最大最小灰度值计算得出的,旨在将图像的灰度范围分成三个等分,以较大的灰度值作为阈值。
-
二值化处理:利用计算得到的阈值 (T),对车牌图像进行二值化处理。这里使用
im2bw函数,将图像中灰度值大于阈值的像素置为白色(1),灰度值小于等于阈值的像素置为黑色(0),得到二值化后的图像app.img_33。 -
返回结果:将二值化后的图像转换为RGB格式,并返回结果。
算法实现
% func33:车牌二值化
function img_out = func33(app)
% 获取最大最小灰度值
c_max = double(max(max(app.img_32)));
c_min = double(min(min(app.img_32)));
% 分为三个灰度级,取较亮的二三灰度级之间的边界值作为阈值
T = round(c_max-(c_max-c_min)/3); % T 为二值化的阈值
app.img_33= im2bw(app.img_32,T/256);
% 得到结果
img_out = app.bw2rgb(app.img_33);
end
实验结果

步骤11:去除车牌左右边框
算法原理
在粗定位图像中,车牌的上下边框很容易通过统计白色像素点来确定并排除,但在垂直方向上,如果依然通过单纯地统计垂直方向上的白色像素点,占满整列的左右边框很难和与占满整列的车牌字母区分开。
因此,我们可以通过投影的宽度来排除掉边框,并将这些小于宽度阈值的投影区域像素置为0。
算法实现
%% func34:移除左右边框
function img_out = func34(app)
% 读取车牌二值图像
plate_bw = app.img_33;
% 垂直投影
vertical_projection = sum(plate_bw, 1);
% 找到左边框和右边框的位置
left_border = find(vertical_projection > 0, 1, 'first');
right_border = find(vertical_projection > 0, 1, 'last');
% 设置投影宽度阈值
threshold = 50;
% 检查左边框附近的投影宽度
for i = left_border:-1:1
if vertical_projection(i) < threshold
left_border = i + 1;
break;
end
end
% 检查右边框附近的投影宽度
for i = right_border:length(vertical_projection)
if vertical_projection(i) < threshold
right_border = i - 1;
break;
end
end
% 裁剪图像,去除左右边框
plate_cropped = plate_bw(:, left_border:right_border);
% 显示结果
figure;
subplot(1, 2, 1);
imshow(plate_bw);
title('原始车牌二值图像');
subplot(1, 2, 2);
imshow(plate_cropped);
title('去除左右边框后的车牌二值图像');
img_out = app.bw2rgb(plate_cropped);
end
实验结果

步骤12:根据投影分割字符
算法原理
为了方便计算机识别字符,我们需要先把字符分割成单一字符,减少计算机的运算量,提高识别率。
在这里我们使用投影分割的办法,利用 sum 函数统计出垂直方向上的像素综合,然后在波谷的位置进行切割。
算法实现
%% funcC1:字符切割
function img_out = funcC1(app)
% 读取车牌二值图像
plate_bw = double(app.img_35);
[p,q]=size(plate_bw);
% X3 = zeros(1,q); % 产生 1 行 q 列全零数组
X3 = sum(plate_bw,1); % 垂直投影累计
PxR=q; % 字符右边界
PxL=q; % 字符左边界
% 从车牌右侧开始寻找
for i=1:6
while((X3(1,PxR)<3)&&(PxR>0))
PxR=PxR-1; % 从图像最右边找字符的右边界
end
PxL=PxR; % 更新字符的左边界为已找到的右边界
while(((X3(1,PxL)>=3))&&(PxL>0)||((PxR-PxL)<15))
PxL=PxL-1; % 从图像右边界向左,找字符的左边界
end
CharSplit=plate_bw(:,PxL:PxR,:);
% 将 CharSplit 赋值给对应的变量
app.("img_c"+num2str(8-i)) = CharSplit;
img_out{8-i} = app.("img_c"+num2str(8-i)); % 将字符图像存储到输出变量中
PxR=PxL;
end
% =========== 对第一个字符进行特别处理 =========
Px1L=PxL; % 字符 1 右边界初始化为右边 6 个字符的左边界
while((X3(1,Px1L)<3)&&(Px1L>0))
Px1L=Px1L-1;
end
app.img_c1 = plate_bw(:,1:Px1L,:);
img_out{1} = app.img_c1; % 将第一个字符图像存储到输出变量中
% 单独输出窗口
% figure;
% for i = 1:7
% subplot(1,7,i),imshow(app.("img_c" + num2str(i)));
% end
% 将输出图像转为 rgb 便于在 Image 组件显示
for i=1:7
img_out{i}=app.bw2rgb(img_out{i});
end
end
这个函数会输出一个包含 7 个字符二值图的图像数组 img_out,通过 img_out{i} 来访问,比如:
img_rgb = app.funcC1();
for i = 1:7
app.("ImageC" + num2str(i)).ImageSource = img_rgb{i};
end
实验结果

步骤13:准备字符模板
算法原理
为了满足下一步的字符的特征识别、模板匹配,我们需要自己准备字符模板,可以访问 EasyPR 项目中的训练数据,也可以拍一些清晰的车牌照片再执行上面的步骤,自己制作字符模板。
实验结果



步骤14:识别单个字符
算法原理
在上一步中,我们已经分割除了车牌的单个字符,并存储在了全局变量 app.img_c1 到 app.img_c7 中,为了简单理解字符识别的过程,这里采用最简单的模板匹配算法,即直接对比两幅同样大小的图片的相似程度。
后续如果要提高识别准确率,可以制作更多车牌的样板,采用卷积神经网络计算或者机器学习计算出模型,使用训练出的模型来对车牌文字进行识别。
算法实现
加载模板
首先,我们要把准备好的模板加载进来,加载模板的函数如下:
这里的模板会自动读取 Template 目录下的所有图像和文件名,所以当模板比较模糊的时候,或者某个字有更好的模板的时候,直接替换文件即可,不用修改代码。
%% 自定义函数:加载汉字模板
function Chinese = LoadChinese(app)
% 获取当前工作目录
currentDir = pwd;
folderPath = fullfile(currentDir, 'Template', 'Chinese');
% 获取文件夹中的所有文件
filePattern = fullfile(folderPath, '*.bmp');
bmpFiles = dir(filePattern);
numFiles = length(bmpFiles);
% 初始化汉字模板单元格数组
Chinese = cell(2, numFiles);
% 逐个加载、处理汉字模板
for i = 1:numFiles
% 拼接完整的文件路径
filePath = fullfile(folderPath, bmpFiles(i).name);
% 加载图像文件
img = imread(filePath);
% 二值化处理、反转处理、统一化大小为 [32,16]
img = imcomplement(img);
img = rgb2gray(img);
img = imbinarize(img);
img = imresize(img, [32, 16]);
% 存储到 Chinese 单元格数组中
Chinese{1}{i} = img;
[~, fileName, ~] = fileparts(bmpFiles(i).name);
Chinese{2}{i} = fileName;
end
end
%% 自定义函数:加载数字模板
function Numbers = LoadNumbers(app)
% 获取当前工作目录
currentDir = pwd;
folderPath = fullfile(currentDir, 'Template', 'Numbers');
% 获取文件夹中的所有文件
filePattern = fullfile(folderPath, '*.bmp');
bmpFiles = dir(filePattern);
numFiles = length(bmpFiles);
% 初始化数字模板单元格数组
Numbers = cell(2, numFiles);
% 逐个加载、处理数字模板
for i = 1:numFiles
% 拼接完整的文件路径
filePath = fullfile(folderPath, bmpFiles(i).name);
% 加载图像文件
img = imread(filePath);
% 二值化处理、反转处理、统一化大小为 [32,16]
img = rgb2gray(img)
img = imresize(imcomplement(imbinarize(img)), [32, 16]);
% 存储到 Numbers 单元格数组中
Numbers{1}{i} = img;
[~, fileName, ~] = fileparts(bmpFiles(i).name);
Numbers{2}{i} = fileName;
end
% 单独输出展示
% figure;
% for i = 1:length(fileNames)
% img = uint8(Numbers{i} * 255);
% subplot(1,length(fileNames),i);imshow(img)
% end
end
%% 自定义函数:加载字母模板
function Alphabet = LoadAlphabet(app)
% 获取当前工作目录
currentDir = pwd;
folderPath = fullfile(currentDir, 'Template', 'Alphabet');
% 获取文件夹中的所有文件
filePattern = fullfile(folderPath, '*.bmp');
bmpFiles = dir(filePattern);
numFiles = length(bmpFiles);
% 初始化数字模板单元格数组
Alphabet = cell(2, numFiles);
% 逐个加载、处理数字模板
for i = 1:numFiles
% 拼接完整的文件路径
filePath = fullfile(folderPath, bmpFiles(i).name);
% 加载图像文件
img = imread(filePath);
% 二值化处理、反转处理、统一化大小为 [32,16]
img = rgb2gray(img)
img = imresize(imcomplement(imbinarize(img)), [32, 16]);
% 存储到 Numbers 单元格数组中
Alphabet{1}{i} = img;
[~, fileName, ~] = fileparts(bmpFiles(i).name);
Alphabet{2}{i} = fileName;
end
% 单独输出展示
% figure;
% for i = 1:length(fileNames)
% img = uint8(Alphabet{i} * 255);
% subplot(1,length(fileNames),i);imshow(img)
% end
end
字符比对
加载完模板后,要比对字符与模板的匹配率,这里用到了 MATLAB 自带的 corr2 函数
%% 自定义函数:识别车牌第 1 位:汉字
function result = IdentifyChinese(app,Chinese,ch)
num = length(Chinese);
maxSimilarity = 0;
bestMatchIndex = 0;
% disp(size(ch));
% disp(size(Chinese{1}))
% 遍历每个模板图像
for n = 1:num
% 计算图像之间的相关系数
similarity = corr2(ch, Chinese{1}{n});
assignin("base","similarity",similarity);
% 更新最佳匹配
if similarity >= maxSimilarity
maxSimilarity = similarity;
bestMatchIndex = n;
end
end
% 返回对应的汉字
assignin("base","Index",bestMatchIndex);
result = Chinese{2}{bestMatchIndex};
end
%% 自定义函数:识别车牌第 2 位:字母
function result = IdentifyAlphabet(app,Letter,ch)
num = length(Letter);
maxSimilarity = 0;
bestMatchIndex = 0;
for n=1:num
% 计算图像之间的相关系数
similarity = corr2(ch, Letter{1}{n});
% 更新最佳匹配
if similarity >= maxSimilarity
maxSimilarity = similarity;
bestMatchIndex = n;
end
end
result = Letter{2}{bestMatchIndex}; % ASCII 转义字符
end
%% 自定义函数:识别车牌后 5 位:数字或字母
function result = IdentifyNumbers(app,Number,ch)
num = length(Number);
maxSimilarity = 0;
bestMatchIndex = 0;
for n=1:num
% 计算图像之间的相关系数
similarity = corr2(ch, Number{1}{n});
% 更新最佳匹配
if similarity >= maxSimilarity
maxSimilarity = similarity;
bestMatchIndex = n;
end
end
% 返回对应的数字或字母
result = Number{2}{bestMatchIndex};
% if bestMatchIndex<=10
% base = 47;
% result = char(base + bestMatchIndex);
% else
% base = 64;
% result = char(base + bestMatchIndex);
% end
end
函数调用
利用上面写好的加载模板方法和识别字符方法,再整合到 funcC2 函数中,直接输出字符串。
% funcC2:字符识别
function funcC2(app)
% A. 加载模板库
Chinese = app.LoadChinese();
Alphabet = app.LoadAlphabet();
Numbers = app.LoadNumbers();
% B. 特征匹配
results{1} = app.IdentifyChinese(Chinese,app.img_c1);
results{2} = app.IdentifyAlphabet(Alphabet,app.img_c2);
results{3} = app.IdentifyNumbers(Numbers,app.img_c3);
results{4} = app.IdentifyNumbers(Numbers,app.img_c4);
results{5} = app.IdentifyNumbers(Numbers,app.img_c5);
results{6} = app.IdentifyNumbers(Numbers,app.img_c6);
results{7} = app.IdentifyNumbers(Numbers,app.img_c7);
% C. 展示结果
% 将结果连接成一个字符串
resultString = '';
for i = 1:numel(results)
resultString = [resultString, results{i}, ' '];
end
% 使用 msgbox 展示结果
% msgbox({'识别结果', resultString});
% 展示结果
app.LabelPlateNumber.Text = ['车牌号码:', resultString];
end
实验结果

保存二值图作为模板
算法原理
既然前面都经过了那么多图像处理的步骤,那么我们直接可以把得到的模板图像保存下来,用来扩展我们的模板库,只需要简单的文件写入操作。
算法实现
创建一个 Button,创建回调函数,代码如下:
function ButtonPushed(app, event)
% 创建 Output 文件夹
outputFolder = fullfile(pwd, 'Output');
if ~exist(outputFolder, 'dir')
mkdir(outputFolder);
end
% 保存 app.img_c1 到 app.img_c7 的图像
for i = 1:7
img_name = ['img_c', num2str(i)];
img = app.(img_name);
if ~isempty(img)
% 反转二值图像
inverted_img = imcomplement(img);
% 将二值图像转换为 RGB
rgb_img = cat(3, inverted_img, inverted_img, inverted_img);
% 构造保存路径
savePath = fullfile(outputFolder, ['Char_', num2str(i), '.bmp']);
% 保存图像
imwrite(rgb_img, savePath);
end
end
% 提示框
msgbox('反转后的 RGB 图像已保存至 Output 文件夹下');
end
实验结果
其实可以再改进一下,直接把文件命名为暂时识别到的。
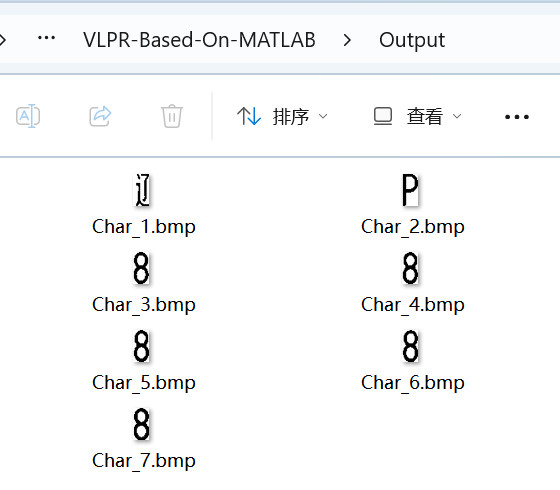
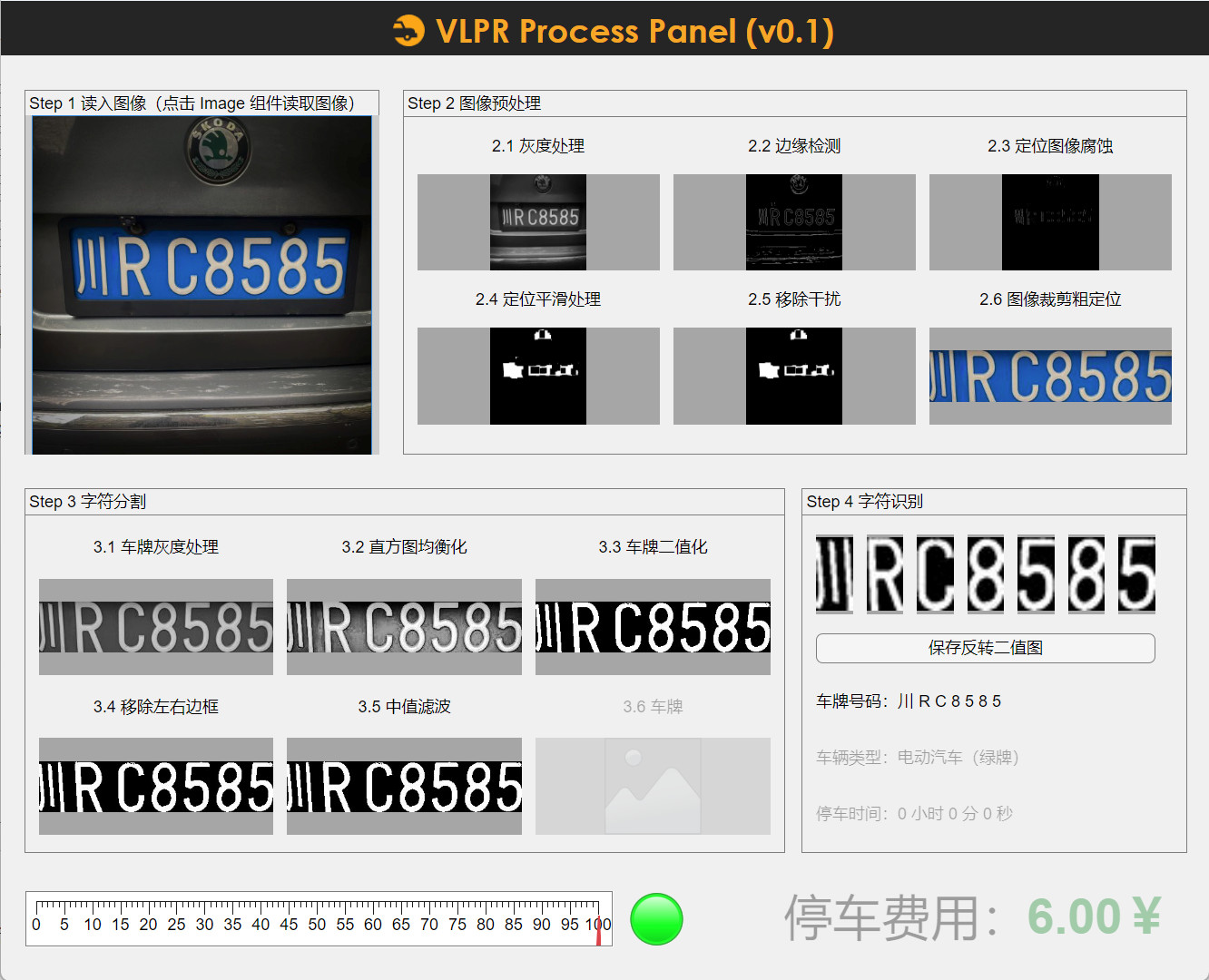
功能测试展示
创新点
动态加载字符模板
很多开源项目和 CSDN 上的教程都是使用多行代码来加载字符模板的,这样效率低不说,而且代码的维护性也很低,如果文件改名或是改路径了,要修改多行代码。
而且很多项目的模板文件明明全是数字,不如干脆直接给模板命名为模板代表的含义,然后让 MATLAB 动态加载目录下的所有文件,并读取文件名,再将图像数据和文件名保存到结构体数组或是 cell 型数组中,这样不仅不用手动对应 Load 函数和 Identify 函数,而且也有利于模板文件的更新。降低了代码与文件、代码与代码之间的耦合性。
%% 自定义函数:识别车牌第 1 位:汉字
function result = IdentifyChinese(app,Chinese,ch)
num = length(Chinese);
maxSimilarity = 0;
bestMatchIndex = 0;
% 遍历每个模板图像
for n = 1:num
% 计算图像之间的相关系数
similarity = corr2(ch, Chinese{1}{n});
assignin("base","similarity",similarity);
% 更新最佳匹配
if similarity >= maxSimilarity
maxSimilarity = similarity;
bestMatchIndex = n;
end
end
% 返回对应的汉字
assignin("base","Index",bestMatchIndex);
result = Chinese{2}{bestMatchIndex};
end
保存二值图作为模板
当遇到清晰的车牌图片或是很典型的车牌图片时,我们完全可以直接将其作为模板,而不是自己再去 Photoshop 转化为二值图了,比较前面都已经进行了那么多步图像处理了,不存白不存。
为了方便开发者识别,最好保存为白底黑字的模板。
除此之外,保存一些典型模板还有利于程序在后期升级为由 SVM 等机器学习算法的训练模型识别车牌。
添加任务进程状态条
心得体会
在制作大作业的过程当中,能够切身体会图像处理的过程真的是很精妙,很理性美。奈何我为人感性,很多算法理解不到位,想法很多但是做不出来。现在这个车牌识别系统甚至只能准确识别出几张车牌,因为算法特别不完善,以下情况都没有被考虑进去:
- 银色车身或白色车身亮度比车牌大,所以二值转化的时候会截取车身而不是车牌
- 黄色车牌的背景明度比字号大,黄色车牌需要反转图像
- 白色车钉会影响蓝色车牌的字符识别,比如数字 3 加上车钉有可能被识别为 9
- 车牌上下的销售公司也是白色字体,很容易被截取进去
- 有的车身会有亮色线条穿过,如果把腐蚀面积加大,车牌字母又会被腐蚀掉
不过对于上述问题,已经有大概的解决思路,比如我们可以先执行直方图均衡化,再通过阈值区分亮暗像素,如果亮色像素明显多余暗像素,证明车身偏亮,在裁剪之前就需要反转图像,裁剪之后再反转回来便于进行后续的字符切割和识别。但是由于 MATLAB 的技术不精加上截至日期将近时间紧迫,暂时没法解决了,只能祈祷这个 Repo 还会更新吧。
通过这次大作业,真的体会到了 MATLAB 编程的乐趣和图像处理的精妙,看着图像一步一步变灰、测出边缘、边缘的白色像素逐渐扩张,会想起课上的知识,感觉这些像素就像是活的微生物一样随着规则生长消失,很有成就感。
但是一出现稍微不同的情况,实验结果就截然不同,程序就会报错。可能这就是科研的乐趣吧,经常能刷到段子——做实验的时候,连你心情怎么样,你做实验前吃的啥,做实验的动作都要记录下来,一个微小的变量就可能导致你复刻不出来。这个心情现在我也能体会了。
参考链接
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝